flowchart LR A(Variabele) --> C[Categoriaal] A --> K[Kwantitatief] C --> N[Nominaal] C --> O[Ordinaal] K --> I[Interval] K --> R[Ratio]
2 Data en Variabelen
IntroLeerdoelen
Data bestaat uit waarnemingen van meetgegevens, dat zijn de variabelen. In dit hoofdstuk wordt uitgelegd welke soort variabelen er zijn en welke bewerkingen je mag toepassen.
Wanneer je data uit externe bronnen importeert, heb je geen controle over de indeling en het type gegevens en de manier waarop de data is georganiseerd. Voordat je met de analyse kunt beginnen moet je daarom vaak veel tijd steken om de data te herstructureren. Het tweede deel van dit hoofdstuk gaat hierover.
2.1 Variabelen
Bij het importeren van de gegevens heb je de variabelen al gedefinieerd en zijn ze van een naam voorzien. Je moet verder ook nog weten wat voor een soort waarden de variabele kan hebben om later te kunnen bepalen welke statistische methodes geschikt zijn voor de variabele. In grote lijnen zijn alle variabelen ofwel kwantitatieve (numerieke) variabelen waarvan de gegevens uit een getelde of gemeten hoeveelheid bestaat, of categoriale variabelen waarvan de gegevens groepen (categorieën) vertegenwoordigen. Zo is een variabele weekomzet een kwantitatieve variabele omdat de waarden hiervan hoeveelheden zijn. En een variabele als geslacht met de categorieën Man en Vrouw is een categoriale variabele.
Soms moet je een kwantitatieve variabele verder specificeren als discreet of continu. Discrete kwantitatieve variabelen hebben waarden die voortkomen uit tellingen, ze vertegenwoordigen een aantal van iets, zoals het aantal leerlingen in een klas. Continue kwantitatieve variabelen hebben waarden die voortkomen uit metingen, zoals de lengte van een persoon, welke in principe elke waarde binnen een interval kan aannemen (afhankelijk van de nauwkeurigheid van het meetinstrument).
2.1.1 Meetniveaus
Variabelen worden in vier meetniveaus (schalen) ingedeeld: nominaal, ordinaal, interval en ratio.
Nominaal
Een variabele op nominaal niveau (ook wel een categorische variabele genoemd) is een variabele waarbij de waarden (categorien) uit namen (naam in het Latijn is nomen) bestaan waarbij ook geen relatie tussen de mogelijkheden bestaat. De gegevens zijn kwalitatief of beschrijvend. De waarden hebben ook geen logische volgorde. Je kunt niet aangeven dat de ene waarde groter is dan de andere waarde, of de gemiddelde waarde berekenen. Het enige dat je kunt zeggen is dat de mogelijkheden van elkaar verschillen.
Voorbeelden: geslacht, nationaliteit, godsdienst, woonplaats, burgerlijke staat, oogkleur, beroep, studierichting, industrietak, ….
Ordinaal
Variabelen op ordinaal niveau hebben iets meer structuur dan nominale variabelen, maar niet veel. Bij een ordinale variabele is er een natuurlijke zinvolle manier om de waarden te ordenen, bijvoorbeeld van klein naar groot of van meer dan minder. Voorbeelden: restaurantclassificatie (aantal sterren), enquêtevragen (Likertschalen: 1=zeer goed, 2=goed, …), plaats in wedstrijduitslag (1, 2, 3, …). Met de waarden kun je geen rekenkundige bewerkingen uitvoeren, zoals een gemiddelde berekenen.
Zo is een restaurant met 2 sterren beter dan eentje met 1 ster, maar je kunt niet zomaar zeggen 2 keer beter. En bij de uitslag van een maraton is de eerste sneller dan de tweede en is deze weer sneller dan de derde, enz. Maar het verschil tussen de eerste plaats en de tweede plaats kan anders zijn dan het verschil tussen de tweede en de derde plaats.
Voorbeelden: beoordeling (1=zeer slecht, 2=slecht, 3=matig, 4=goed, 5=zeer goed), medaille (goud, zilver, brons), T-shirt maten (S, M, L, XL), …
Interval
In tegenstelling tot nominale en ordinale variabelen, zijn variabelen op intervalniveau en rationiveau variabelen waarbij de numerieke waarde echt van betekenis is. De gegevens zijn kwantitatief, maar hebben geen “natuurlijk” nulpunt. De keuze van een nulpunt is vaak arbitrair. De verschillen tussen de waarden (intervallen) heeft wel betekenis. Sommige rekenkundige bewerkingen kun je uitvoeren zoals optellen, aftrekken, gemiddelde bepalen. Maar je kunt niet vermenigvuldigen of delen.
Een goed voorbeeld van een variabele op intervalniveau is het meten van temperatuur in graden Celsius. Het nulpunt van 0°C is willekeurig gekozen, namelijk de temperatuur waarbij water bevriest. De verschillen hebben betekenis. Zo is het verschil tussen 12°C en 18°C even groot als het verschil tussen 18°C en 24°C. Maar je kunt niet zeggen dat 24°C twee keer zo warm is als 12°C.
Voorbeelden: jaartal, datum, kloktijd, …
Ratio
Bij een variabele op rationiveau (verhoudingsniveau) is er een echt nulpunt, waarbij nul ook echt nul betekent. Een ratiovariabele meet dus de omvang van de variabele. Bij deze variabelen mag je wel vermenigvuldigen en delen. Zo is een salaris van €4000 twee keer zo groot als een salaris van €2000.
Voorbeelden: inkomen, uitgaven, gewicht, lengte, snelheid, massa, reactietijd
Samengevat
- kwalitatieve variabele (nominaal, ordinaal)
- wordt niet numeriek gemeten, elke waarde heet ook wel categorie
- geen rekenkundige bewerkingen, wel aantallen tellen per categorie
- kwantitatieve variabele (interval, ratio)
- wordt numeriek gemeten
- rekenkundige bewerkingen zijn mogelijk
2.1.2 Continue - discrete variabelen
Er is nog een tweede soort onderscheid waar je op bedacht moet zijn bij de typen variabelen, namelijk het onderscheid tussen continue variabelen en discrete variabelen.
Continue variabele: een variabele waarbij het voor elke twee waarden die je kunt bedenken, logischerwijs altijd mogelijk is dat er nog een andere waarde tussen ligt.
Discrete variabele is in feite een variabele die niet continu is. Bij een discrete variabele is het soms zo dat er daartussenin niets mogelijk is.
| meetniveau | continu | discreet |
|---|---|---|
| nominaal | \(\checkmark\) | |
| ordinaal | \(\checkmark\) | |
| interval | \(\checkmark\) | \(\checkmark\) |
| ratio | \(\checkmark\) | \(\checkmark\) |
Opmerking
Een jaartal, bijvoorbeeld het bouwjaar van een auto, wordt doorgaans beschouwd als een discrete kwantitatieve variabele en niet als een ordinale variabele. Echter afhankelijk van de context kan het nodig zijn om een jaarvariabele als een ordinale variabele te behandelen.
Testvragen
Welk type variabele is de medaillesoort die een atleet op de Olympische spelen kan winnen?
Welk type variabele is de tijd van een atleet voor het lopen van een marathon?
De Nederlandse nationale politie kent een aantal rangen. Welk type variabele is de rang?
2.2 Gestructureerde gegevens
Vaak zijn de gegevens zijn niet goed gestructureerd, waardoor je niet met draaitabellen kunt werken of de gewenste grafieken niet kunt maken. Wanneer de gegevens goed gestructureerd zijn kun je ze gemakkelijker modelleren, visualiseren en transformeren waardoor de analyse eenvoudiger wordt.
Gestructureerde gegevens moeten voldoen aan de volgende voorwaarden:
Elke gemeten variabele staat in een kolom.
Elke waarneming van de variabele staat in een rij.

In Tabel 2.2 staan de gegevens van een meting bij een klein denkbeeldig experiment in een formaat dat je (vooral in spreadsheets) veel tegenkomt.
Deelnemer | Behandeling A | Behandeling B |
|---|---|---|
Melissa | 6 | 7 |
Roger | 18 | |
Vicky | 4 | 1 |
Wanneer je de rijen en kolommen verwisselt heb je dezelfde gegevens, maar de tabel ziet er dan iets anders uit, zie Tabel 2.3.
Behandeling | Melissa | Roger | Vicky |
|---|---|---|---|
Behandeling A | 6 | 4 | |
Behandeling B | 7 | 18 | 1 |
In feite telt deze gegevensverzameling drie variabelen: Naam, Behandeling en Meetwaarde. Gestructureerd ziet deze gegevensverzameling er uit zoals in Tabel 2.4.
Deelnemer | Behandeling | Meetwaarde |
|---|---|---|
Melissa | Behandeling A | 6 |
Melissa | Behandeling B | 7 |
Roger | Behandeling A | |
Roger | Behandeling B | 18 |
Vicky | Behandeling A | 4 |
Vicky | Behandeling B | 1 |
Dit maakt de waarden, variabelen en waarnemingen duidelijker.
Echte gegevensverzamelingen zijn vaak op bijna elke denkbare manier in strijd met de voorwaarden voor gestructureerde gegevens. De meest voorkomende problemen bij niet goed gestructureerde gegevensverzamelingen zijn:
- Kolomkoppen bevatten waarden van een variabele i.p.v. een variabelenaam.
- Combinatie van variabelen in een kolom.
- Variabelen in zowel rijen als kolommen.
In de taken hierna zullen in kleine voorbeelden deze problemen gedemonstreerd worden en opgelost worden met behulp van Power Query.
2.2.1 Kolomkoppen met waarden
Een veel voorkomende vorm van een gegevensverzameling is een tabelvorm waarbij de kolomkoppen waarden zijn en geen variabelenamen. Tabel 2.5 is hier een voorbeeld van. Hierin staat het aantal mannelijke en vrouwelijke studenten dat een bepaalde score (A t/m E) behaald heeft.
score | man | vrouw |
|---|---|---|
A | 5 | 3 |
B | 10 | 5 |
C | 9 | 9 |
D | 6 | 5 |
E | 1 | 7 |
Deze gegevensverzameling heeft in feite drie variabelen:
score- met de waardenAt/mEgeslacht- met de waardenmanenvrouwaantal- met het aantal keren dat de score behaald is, de frequentie
Het probleem is dus dat de waarden van de variabele geslacht in twee kolomkoppen staat.
De eerste variabele score is al een kolom, dat moet dus zo blijven. Voor de variabelen geslacht en aantal moeten nieuwe kolommen gemaakt worden. Voor elke combinatie van score en geslacht moet een rij gemaakt worden.
Taak 2.1 Hulpbestand: scores1.xlsx
Open het hulpbestand.
Selecteer een willekeurige cel met gegevens en kies tab Gegevens > Vanaf blad (Gegevens ophalen en transformeren). Het dialoogvenster Tabel maken verschijnt, waarin de tabelgegevens gespecificeerd kunnen worden. Het gegevensgebied is standaard al goed ingevuld.
Zorg er voor dat de optie voor kopteksten geselecteerd is en klik OK. Op het werkblad worden de gegevens allereerst in een Excel tabel omgezet. Daarna wordt in een nieuw venster de Power Query-editor opgestart die de gegevens uit de tabel inleest.
Selecteer in de Power Query editor de eerste kolom
score.Kies tab Transformeren > Draaitabel opheffen voor kolommen (groep Alle kolommen) > Draaitabel voor andere kolommen opheffen. Er worden twee nieuwe kolommen gemaakt. Een kolom
Kenmerk(met de waarden voor variabelegeslacht) en een kolomWaardemet de aantallen. En voor elke combinatie vanscoreengeslachtis een rij gemaakt.Selecteer kolom
Kenmerk, dan Rechter muisklik > Naam wijzigen en wijzig de naam ingeslacht.Wijzig op dezelfde manier de naam van kolom
Waardeinaantal.Kies tab Startpagina > Sluiten en laden > Sluiten en laden.
Het resultaat is een tabel met gestructureerde gegevens. Elke kolom is één variabele en elke rij is één waarneming.
score | geslacht | aantal |
|---|---|---|
A | man | 5 |
A | vrouw | 3 |
B | man | 10 |
B | vrouw | 5 |
C | man | 9 |
C | vrouw | 9 |
D | man | 6 |
D | vrouw | 5 |
E | man | 1 |
E | vrouw | 7 |
2.2.2 Kolomkoppen zijn gecombineerde variabelen
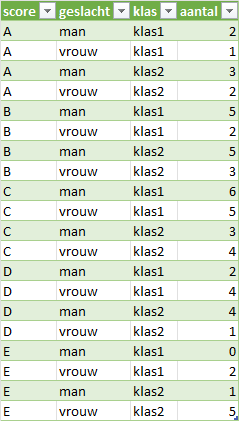
Soms zijn kolommen een combinatie van meerdere onderliggende variabelen. Dit is het geval bij de gegevensverzameling in Tabel 2.7. Deze is gelijkwaardig aan die in de vorige taak. Alleen zijn er nu twee verschillende klassen (klas1 en klas2) en staat het aantal voor elk geslacht in elke klas in een eigen kolom. Ook in deze gegevensverzameling zijn de kolomkoppen waarden van variabelen. Maar er zijn twee variabelen, geslacht en klas, in één kolom gecombineerd.
score | man_klas1 | vrouw_klas1 | man_klas2 | vrouw_klas2 |
|---|---|---|---|---|
A | 2 | 1 | 3 | 2 |
B | 5 | 2 | 5 | 3 |
C | 6 | 5 | 3 | 4 |
D | 2 | 4 | 4 | 1 |
E | 0 | 2 | 1 | 5 |
Taak 2.2 Hulpbestand: scores2.xlsx
Open het hulpbestand.
Selecteer een willekeurige cel met gegevens en kies tab Gegevens > Vanaf blad (Gegevens ophalen en transformeren). Het dialoogvenster Tabel maken verschijnt, waarin de tabelgegevens gespecificeerd kunnen worden. Het gegevensgebied is standaard al goed ingevuld.
Zorg er voor dat de optie voor kopteksten geselecteerd is en klik OK. Op het werkblad worden de gegevens allereerst in een Excel tabel omgezet. Daarna wordt in een nieuw venster de Power Query-editor opgestart die de gegevens uit de tabel inleest.
Selecteer in de Power Query editor de eerste kolom
score.Kies tab Transformeren > Draaitabel opheffen voor kolommen (groep Alle kolommen) > Draaitabel voor andere kolommen opheffen. Er worden twee nieuwe kolommen gemaakt. Een kolom
Kenmerk(met de waarden voorgeslacht_klas) en een kolomWaardemet de aantallen. En voor elke combinatie vanscoreengeslacht_klasis een rij gemaakt.Selecteer kolom
Kenmerken kies tab Transformeren > Kolom splitsen (groep Kolom Tekst) > Op scheidingsteken. In het dialoogvenster is reeds het juiste scheidingsteken (_) waarop gesplitst moet worden, geselecteerd.Klik OK. De kolom
Kenmerkis gesplitst in kolomKenmerk.1(met de waarden voor variabelegeslacht) enKenmerk.2(met de waarden voor variabeleklas).Wijzig de namen van de kolommen
Kenmerk.1,Kenmerk.2enWaardein respectievelijkgeslacht,klasenaantal.Kies tab Startpagina > Sluiten en laden > Sluiten en laden.
Het resultaat is een tabel met gestructureerde gegevens. Elke kolom is één variabele en elke rij is één waarneming.
2.2.3 Variabelen in rijen en kolommen
Een meer gecompliceerde vorm van rommelige gegevens krijg je wanneer er variabelen in zowel rijen als kolommen staan. In het voorbeeld hierna staan de beoordelingen voor een tussentoets en een eindtoets voor vijf studenten, waarbij elk van hen in precies twee van de vijf mogelijke klassen is geplaatst.
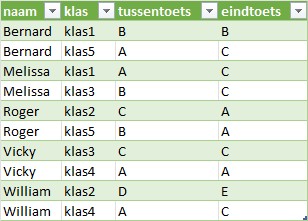
naam | toets | klas1 | klas2 | klas3 | klas4 | klas5 |
|---|---|---|---|---|---|---|
Bernard | tussentoets | B | A | |||
Bernard | eindtoets | B | C | |||
Melissa | tussentoets | A | B | |||
Melissa | eindtoets | C | C | |||
Roger | tussentoets | C | B | |||
Roger | eindtoets | A | A | |||
Vicky | tussentoets | C | A | |||
Vicky | eindtoets | C | A | |||
William | tussentoets | D | A | |||
William | eindtoets | E | C |
De eerste kolom met de variabele naam is in orde en moet zo blijven. De koppen van de laatste vijf kolommen zijn allemaal waarden van de variabele klas. De waarden in de tweede kolom, tussentoets en eindtoets, moeten eigen variabelen worden met als waarde de beoordeling van de student op dit onderdeel.
Taak 2.3 Hulpbestand: scores3.xlsx
Open het hulpbestand.
Selecteer een willekeurige cel met gegevens en kies tab Gegevens > Vanaf blad (Gegevens ophalen en transformeren). Het dialoogvenster Tabel maken verschijnt, waarin de tabelgegevens gespecificeerd kunnen worden. Het gegevensgebied is standaard al goed ingevuld.
Zorg er voor dat de optie voor kopteksten geselecteerd is en klik OK. Op het werkblad worden de gegevens allereerst in een Excel tabel omgezet. Daarna wordt in een nieuw venster de Power Query-editor opgestart die de gegevens uit de tabel inleest.
Selecteer in de Power Query editor de laatste vijf kolommen
klas1t/mklas5.Kies tab Transformeren > Draaitabel opheffen voor kolommen (groep Alle kolommen) > Draaitabel opheffen voor kolommen. Er worden twee nieuwe kolommen gemaakt. Een kolom
Kenmerk(met de waarden voor variabeleklas) en een kolomWaardemet de beoordeling. En voor elke combinatie vannaam,toetsenklasis een rij gemaakt.Wijzig de naam van kolom
Kenmerkinklas.Selecteer kolom
toetsen kies tab Transformeren > Draaikolom (groep Alle kolommen). Het dialoogvenster Draaikolom verschijntKies als Waardenkolom
Waarde. En geef onder Geavanceerde opties aan dat er niet samengevoegd moet worden.
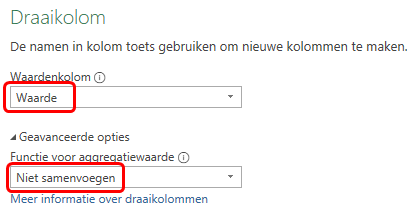
Klik OK.
Kies tab Startpagina > Sluiten en laden > Sluiten en laden.
Het resultaat is een tabel met gestructureerde gegevens. Elke kolom is één variabele en elke rij is één waarneming.
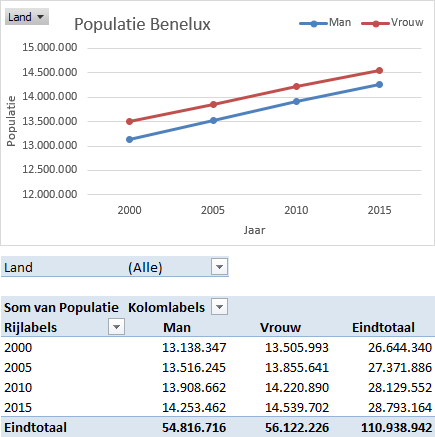
2.3 TAAK: Populatie Benelux
Tabel 2.9 bevat de populatie mannen en vrouwen in de landen van de Benelux voor de jaren 2000, 2005, 2010 en 2015.
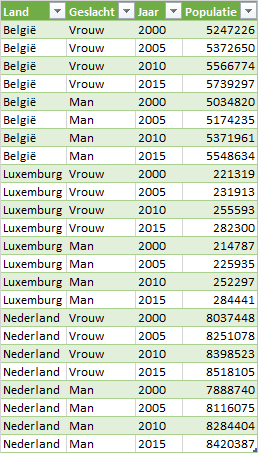
Land | Geslacht | 2000 | 2005 | 2010 | 2015 |
|---|---|---|---|---|---|
België | Vrouw | 5,247,226 | 5,372,650 | 5,566,774 | 5,739,297 |
België | Man | 5,034,820 | 5,174,235 | 5,371,961 | 5,548,634 |
Luxemburg | Vrouw | 221,319 | 231,913 | 255,593 | 282,300 |
Luxemburg | Man | 214,787 | 225,935 | 252,297 | 284,441 |
Nederland | Vrouw | 8,037,448 | 8,251,078 | 8,398,523 | 8,518,105 |
Nederland | Man | 7,888,740 | 8,116,075 | 8,284,404 | 8,420,387 |
Deze gegevens wil je analyseren en bijvoorbeeld de ontwikkeling van de populatie per geslacht per jaar bestuderen en dat eventueel nog per land. Een draaitabel en draaigrafiek lenen zich daar het beste voor.
Echter de gegevens staan niet in een goed gestructureerde Exceltabel. In feite heeft deze tabel vier variabelen: Land, Geslacht, Jaar en Populatie. De eerste twee variabelen staan in een eigen kolom, dat moet zo blijven. De laatste vier kolomkoppen zijn de waarden van de variabele Jaar en de inhoud van deze kolommen is de waarde van de variabele Populatie. De tabel moet dus eerst gestructureerd worden voordat met de analyse begonnen kan worden.
Taak 2.4 Hulpbestand: benelux-populatie.xlsx
Structureren data
Open het hulpbestand.
Selecteer een willekeurige cel met gegevens en kies tab Gegevens > Vanaf blad (Gegevens ophalen en transformeren). Het dialoogvenster Tabel maken verschijnt, waarin de tabelgegevens gespecificeerd kunnen worden. Het gegevensgebied is standaard al goed ingevuld.
Zorg er voor dat de optie voor kopteksten geselecteerd is en klik OK. Op het werkblad worden de gegevens allereerst in een Excel tabel omgezet. Daarna wordt in een nieuw venster de Power Query-editor opgestart die de gegevens uit de tabel inleest.
Selecteer in de Power Query editor de eerste twee kolommen, met
LandenGeslacht.Kies tab Transformeren > Draaitabel opheffen voor kolommen (groep Alle kolommen) > Draaitabel voor andere kolommen opheffen. Er worden twee nieuwe kolommen gemaakt. Een kolom
Kenmerk(met de waarden voor variabeleJaar) en een kolomWaardemet de populatiegetallen. En voor elke combinatie vanLand,GeslachtenJaaris een rij gemaakt.
Opmerking
Je had er ook voor kunnen kiezen om de laatste vier kolommen met de jaartallen te selecteren en dan te kiezen voor het opheffen van de draaitabel voor deze kolommen. Dit heeft als nadeel dat de query niet meer goed werkt wanneer er later in de brongegevens een nieuwe kolom met de populatie voor het jaar 2020 wordt toegevoegd.
Wijzig de namen van de kolommen
KenmerkenWaardein respectievelijkJaarenPopulatie.Kies tab Startpagina >Sluiten en laden (groep Sluiten). De gegevens worden nu in een nieuwe tabel in een nieuw werkblad gezet.
De gegevens staan nu in een gestructureerde Excel tabel en zijn nu geschikt voor het maken van draaitabellen en draaigrafieken.
Analyse
- Maak de volgende draaitabel en draaigrafiek.
2.4 Opgaven
Oefening 2.1 waarnemingen en variabelen
In Tabel 2.10 zie je een dataset met een aantal persoonsgegevens.
voornaam | geslacht | haarkleur | lengte | gewicht | iq |
|---|---|---|---|---|---|
Chris | m | bruin | groot | 185 | 95 |
Mari | v | blond | groot | 176 | 104 |
Otto | m | blond | normaal | 181 | 98 |
Peter | m | zwart | normaal | 178 | 108 |
Vicky | v | rood | klein | 164 | 112 |
- Hoeveel waarnemingen en hoeveel variabelen telt de dataset in Tabel 2.10?
- Geef voor elke variabele aan tot welk meetniveau deze variabele behoort.
Oefening 2.2 Tekstberichten
Bij een onderzoek wordt aan personen gevraagd om bij te houden hoeveel tekstberichten ze per dag versturen en hoeveel tijd ze hieraan besteden. Welke variabelen heb je hier en zijn deze discreet of continu?
Oefening 2.3 Koffieprijzen
Het bestand koffieprijzen.xlsx bevat een aantal koffieprijzen van Starbucks, zie de tabel in Tabel 2.11.
Product | Tall | Grande | Venti |
|---|---|---|---|
Caffè Latte | 3.15 | 3.65 | 4.15 |
Cappuccino | 3.15 | 3.65 | 4.15 |
Espresso | 2.05 | 2.55 | |
Caramel Maccchiato | 4.05 | 4.55 | 5.05 |
White Caffè Mocha | 4.05 | 4.55 | 5.05 |
Caffè Mocha | 4.05 | 4.55 | 5.05 |
Vanilla Latte | 3.65 | 4.15 | 4.65 |
Caffè Americano | 2.55 | 3.05 | 3.55 |
Filter Coffee | 2.25 | 2.75 | 3.05 |
- Ga na dat de tabel in feite drie variabelen bevat en dat de waarden van een van de variabelen in de kolomkoppen staat.
- Maak hiervan een gestructureerde dataset.
Oefening 2.4 Kosten levensonderhoud
Om de kosten van levensonderhoud in Europa te vergelijken zijn via de website van Numbeo voor een aantal plaatsen de gemiddelde marktprijzen verzameld voor brood (wit, 500 gram), kaas(lokaal, 1 kg), melk (gewoon, 1 liter) en rijst (wit, 1 kg). De data staan in het bestand levensonderhoud.xlsx. Voor de eerste 10 plaatsen zijn de gegevens te zien in de tabel in Tabel 2.12.
City | Bread | Cheese | Milk | Rice |
|---|---|---|---|---|
Aachen, Germany | 190 | 1,291 | 107 | 313 |
Aberdeen, United Kingdom | 143 | 739 | 143 | 142 |
Alicante, Spain | 146 | 1,429 | 121 | 167 |
Amsterdam, Netherlands | 236 | 1,321 | 142 | 250 |
Antwerp, Belgium | 250 | 1,544 | 111 | 204 |
Athens, Greece | 122 | 1,297 | 158 | 264 |
Augsburg, Germany | 205 | 1,299 | 114 | 321 |
Barcelona, Spain | 172 | 1,426 | 106 | 148 |
- Maak hiervan een gestructureerde dataset.
- In welk land is rijst gemiddeld het goedkoopst en in welk land het duurst?
Tip
De gegevens zijn geïmporteerd van de Numbeo website met Power Query. Desgewenst kun je de gegevens actualiseren door de query opnieuw uit te voeren met Gegevens > Alles vernieuwen > Alles vernieuwen (groep Query’s en verbindingen).
Oefening 2.5 Toets basisschool
Op een bepaalde basischool krijgt elke leerling krijgt in elk kwartaal (Herfst, Winter en Lente) van elk jaar een toets voor rekenen en taal. Het bestand rekenentaal.xlsx bevat een beperkte gegevensverzameling hiervan en is te zien in de tabel in Tabel 2.13.
ID | Toets | Jaar | Herfst | Winter | Lente |
|---|---|---|---|---|---|
1 | Rekenen | 2,017 | 61 | 69 | 63 |
1 | Rekenen | 2,018 | 54 | 86 | 56 |
1 | Taal | 2,017 | 75 | 80 | 75 |
1 | Taal | 2,018 | 50 | 71 | 59 |
2 | Rekenen | 2,017 | 54 | 82 | 56 |
2 | Rekenen | 2,018 | 63 | 73 | 59 |
2 | Taal | 2,017 | 56 | 90 | 52 |
2 | Taal | 2,018 | 77 | 84 | 71 |
3 | Rekenen | 2,017 | 52 | 75 | 54 |
3 | Rekenen | 2,018 | 56 | 86 | 52 |
3 | Taal | 2,017 | 65 | 77 | 54 |
3 | Taal | 2,018 | 59 | 94 | 48 |
De analyse-eenheid is ID-Jaar-Kwartaal. Dus elke waarneming is die van een leerling gedurende een kwartaal in een bepaald jaar.
- Maak hiervan een gestructureerde gegevensverzameling.
- Maak een draaigrafiek (staafdiagram) van de gemiddelde scores voor rekenen en taal per jaar.