6 Prognoses
Voor het schatten van toekomstige waarden zijn verschillende (statistische) technieken beschikbaar. Naast de zeer eenvoudige naïeve prognose komt de meer geavanceerdere exponentïele vereffening (smoothing) aan bod. Ook wordt gekeken naar maatstaven om de nauwkeurigheid van de voorspelde waarden te beoordelen.
6.1 Nauwkeurigheid prognoses
Hoe nauwkeurig zijn de voorspellingen die zijn verkregen met een bepaalde prognosetechniek? Om deze vraag te beantwoorden worden een aantal verschillende kentallen voor de voorspelling van de nauwkeurigheid geïntroduceerd.
Alles begint bij het bepalen van de prognosefout.
\[\text{(prognose)fout} = \text{werkelijke waarde} - \text{voorspelde waarde}\]
Je wilt uiteraard dat de prognosefouten zo klein mogelijk zijn. Omdat de fouten zowel positief als negatief kunnen zijn, heb je niet veel aan het gemiddelde van deze fouten. Vandaar dat altijd de absolute waarde van de fouten genomen wordt.
Er zijn verschillende kentallen ontwikkeld om de nauwkeurigheid te beoordelen. Deze worden meestal met hun Engelstalige afkorting gebruikt. Een paar veel voorkomende kentallen staan in Tabel 6.1 genoemd.
| Kental | Engelstalig | Nederlandstalig |
|---|---|---|
| MAE | Mean Absolute Error | Gemiddelde absolute fout |
| MAPE | Mean Absolute Percentage Error | Gemiddelde absolute procentuele fout |
| MSE | Mean Squared Error | Gemiddelde kwadratische afwijking |
| RMSE | Root Mean Squared Error | Wortel kwadratische afwijking |
Je kunt niet zomaar een van deze kentallen als het beste kental beschouwen. In het algemeen geldt voor elk kental: hoe kleiner de waarde, des te beter.
6.2 Naïeve prognose
Een van de meest eenvoudige prognosemethodes is de naïeve prognose. Hierbij is de prognose op een bepaald tijdstip gelijk aan de waarde op het voorgaande tijdstip. Voor het bepalen hiervan heb je geen ingewikkelde formules nodig. Ondanks dat deze methode erg simpel is, zijn de resultaten vaak verrassend goed. Het is aan te raden om altijd hiermee te starten en daarna de resultaten van andere methodes hiermee te vergelijken.
Taak 6.1 Hulpbestand: benzineverkoop.xlsx
In het bestand is gedurende drie maanden de wekelijkse verkoop van benzine door een brandstofhandelaar bijgehouden. De variabelen zijn week (het weeknummer) en volume (liters x 1000).
Open het hulpbestand.
Maak een grafiek van het verkoopvolume tegen het weeknummer. Eventueel voeg je een horizontale lijn voor het gemiddelde toe.
In Figuur 6.1 zie je dat het verkoopvolume een horizontaal patroon met willekeurige fluctuaties rond het gemiddelde van 71,25 is.
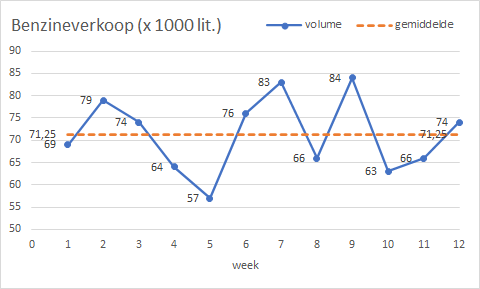
- Maak een naïeve prognose van de wekelijkse verkoop en bereken MAE, MAPE, MSE en RMSE. Het resultaat is te zien in Figuur 6.2.
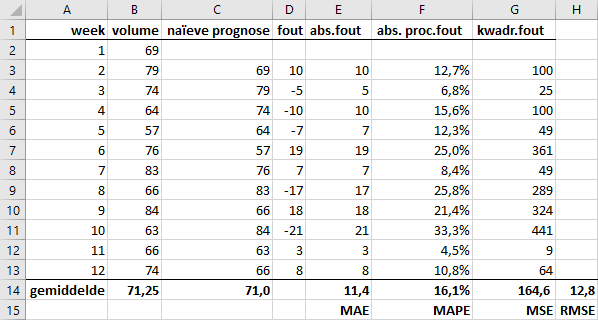
Toelichting:
naïeve prognose: formule C3 wordt=B2enzovoortfout:= volume - naïeve prognoseabsolute fout:= ABS(fout)absolute procentuele fout:= absolute fout / volumekwadratische fout:= fout^2MAE,MAPEenMSEzijn berekend met de formule= GEMIDDELDE(...)RMSE:= WORTEL(MSE)
- Bewaar het bestand voor gebruik in oefeningen hierna.
De prognose voor week 13 is de waarde van de voorgaande periode, dus van week 12.
Voor een tijdreeks met een seizoenscomponent verloopt de naïeve prognose iets anders. In dat geval is de prognose op een bepaald tijdstip gelijk aan de waarde in hetzelfde seizoen in de voorgaande periode.
6.3 Voortschrijdend gemiddelde
Via de methode van het voortschrijdend gemiddelde (zie Hoofdstuk 5) kun je ook prognoses maken. Bij bijvoorbeeld een 3-weeks voortschrijdend gemiddelde kun je het gemiddelde van week 1 tm week 3 gebruiken als prognose voor week 4.
Taak 6.2 Bestand: benzineverkoop.xlsx
Bereken met de formule
=GEMIDDELDE(...)een 3-weeks voortschrijdend gemiddelde van het verkoopvolume en gebruik deze waarde als prognose voor de volgende week.Bereken tevens de MAE, MAPE, MSE en RMSE, analoog aan de oefening bij de naïeve prognose. Het resultaat is te zien in Figuur 6.3.
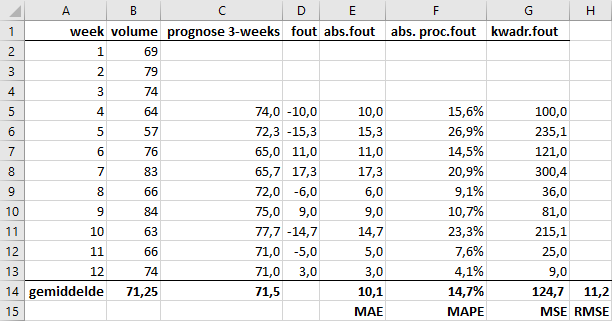
Gelet op de kentallen voor de nauwkeurigheid zie je dat het voortschrijdend gemiddelde iets beter presteert dan de naïeve prognose, maar niet erg veel beter. Je kunt uiteraard proberen of een andere vensterbreedte betere resultaten oplevert.
De prognose voor week 13 is het gemiddelde van week 10 t/m 12.
6.4 Exponentiële demping
Exponentiële demping (effening, smoothing) is een analysemethode voor tijdreeksen waarbij gewichten aan de waarnemingen worden toegekend. Het exponentiële smoothing model heeft de volgende vorm
\(F_{t+1} = \alpha Y_t + (1-\alpha)F_t\) , met
- \(F_{t+1}\): de prognose (Forecast) op tijdstip \(t+1\)
- \(Y_t\): de werkelijke waarde op tijdstip \(t\)
- \(F_t\): de prognose op tijdstip \(t\)
- \(\alpha\): dempingscoëfficient (dempingsconstante) met \(0 \le \alpha \le 1\)
De prognose op tijdstip \(t+1\) is dus een gewogen gemiddelde van de werkelijke waarde op tijdstip \(t\) en de prognose voor tijdstip \(t\), met als wegingsfactoren respectievelijk \(\alpha\) en \(1 - \alpha\). Bij een grote waarde van \(\alpha\) tellen de meest recente waarnemingen zwaarder mee dan de oudere waarnemingen. De prognoses kunnen daardoor sneller reageren op veranderende omstandigheden.
Voor het tijdstip \(t = 1\) (het eerste tijdstip) kun je geen prognose berekenen. Voor tijdstip \(t = 2\) (het tweede tijdstip) wordt de prognose gelijk aan de werkelijke waarde op tijdstip \(t = 1\). Voor alle volgende tijdstippen wordt de prognose berekend met de formule.
Taak 6.3 Bestand: benzineverkoop.xlsx
Gebruik Figuur 6.4 om een prognose van de wekelijkse benzineverkoop te maken via exponentiële demping.
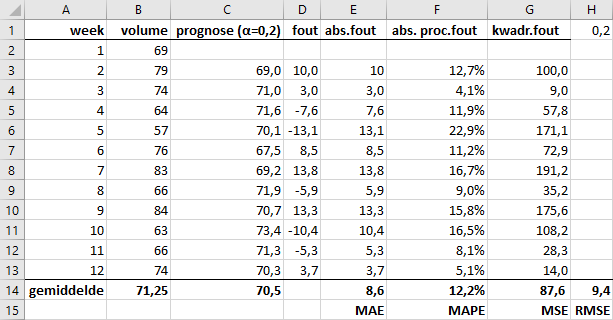
Gelet op de nauwkeurigheidswaarden zijn dit tot nu toe de beste voorspellingen.
De prognose voor week 13 is \(\alpha * \text{laatste week} + (1-\alpha) * \text{een na laatste week}\)
Als de tijdreeks een behoorlijke willekeurige variabiliteit heeft kun je het beste een kleine waarde voor \(\alpha\) nemen. En bij een tijdreeks met weinig variabiliteit heeft een grotere waarde de voorkeur.
De meest wenselijke waarde voor \(\alpha\) is die waarde die de minste fouten oplevert, dus die zorgt voor de laagste gemiddelde kwadratische fout (MSE). In de praktijk ga je meestal proberen of een andere waarde voor \(\alpha\) een nauwkeuriger voorspelling oplevert.
6.4.1 Via Gegevensanalyse
In plaats van zelf de formules te bedenken en in te voeren kun je ook gebruik maken van Gegevensanalyse.
Taak 6.4 Bestand: benzineverkoop.xlsx
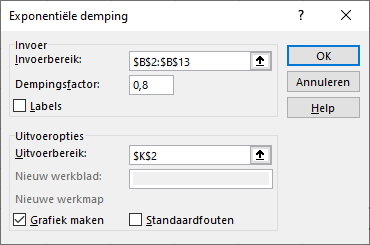
Kies Gegevens > Gegevensanalyse > Exponentiële demping.
In het dialoogscherm, zie Figuur 6.5, specificeer je:
- Invoerbereik: het gebied met de werkelijke waarden.
- Dempingsfactor: de waarde van \(1 - \alpha\)
- Grafiek maken: geeft een lijngrafiek met de werkelijke waarden en de prognoses.
Voor de prognoses krijg je dezelfde resultaten.
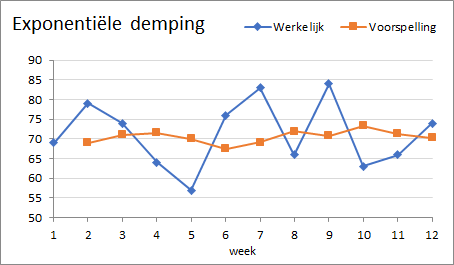
Dit is een eenvoudige en gemakkelijke methode. Daar staat tegenover dat wanneer je met andere waarden voor \(\alpha\) wilt experimenteren, je de procedure steeds weer opnieuw moet uitvoeren.
6.5 Voorspellingenblad
De exponentiële effenings methoden zijn op dit moment de beste en meest gebruikte methoden. Het grootste voordeel van de ETS (Exponential Triple Smoothing) methode is dat deze de mogelijkheid heeft om automatisch seizoenpatronen te ontdekken in de gegevensreeks en voorspellingen met betrouwbaarheidsintervallen kan leveren.
Je kunt het beste deze methode gebruiken wanneer de tijdreeks zowel een trend als een seizoenspatroon laat zien.
In de nieuwere versies van Excel ( Excel 365, Excel 2016, Excel 2019, …) zijn de volgende werkbladfuncties voor het uitvoeren van de ETS methode beschikbaar:
VOORSPELLEN.ETSVOORSPELLEN.ETS.SEASONALITYVOORSPELLEN.ETS.CONFINTVOORSPELLEN.ETS.STAT
Eenvoudiger is het gebruik van het Voorspellingblad of prognosewerkblad dat in die nieuwere Excel versies aanwezig is. Onder de motorkop worden de VOORSPELLEN.ETS functies gebruikt.
Via het Voorspellingenblad wordt een nieuw werkblad gemaakt met daarin een tabel met de oorspronkelijke gegevens en de voorspelde waarden. Deze toekomstige waarden worden berekend op basis van het Holt-Winters ETS algoritme. Ook wordt een grafiek gemaakt met de oorspronkelijke en voorspelde waarden en een aantal schattingen van meetwaarden voor de nauwkeurigheid. Hiermee wordt het maken van geavanceerde prognoses een stuk eenvoudiger.
Taak 6.5 Bestand: verkopen.xlsx (uit Oefening 1.1)
Open het eerder gemaakte bestand
verkopen.xlsx.Selecteer een willekeurige cel in het gegevensgebied.
Kies tab Gegevens > Voorspellingblad (groep Voorspelling). Het dialoogvenster Prognosewerkblad maken verschijnt.
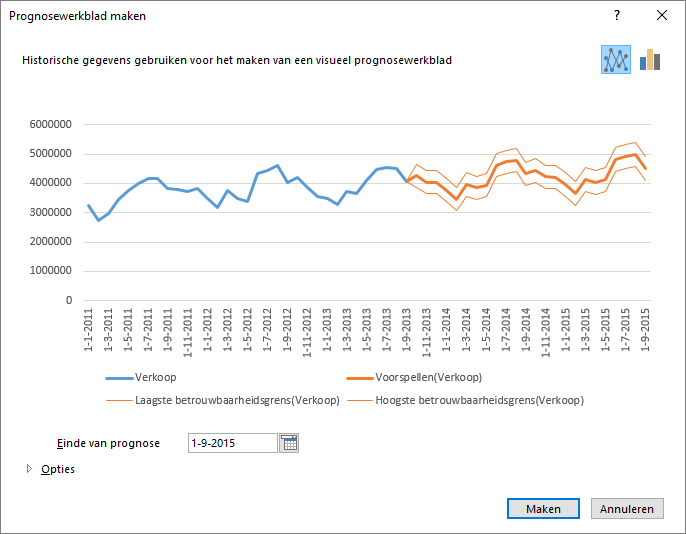
In dit venster kun je een aantal keuzes maken. Zie Bijlage D voor een toelichting.
Stel Einde van prognose in op 1 december 2013.
Klik op [Opties{.uicontrol}.
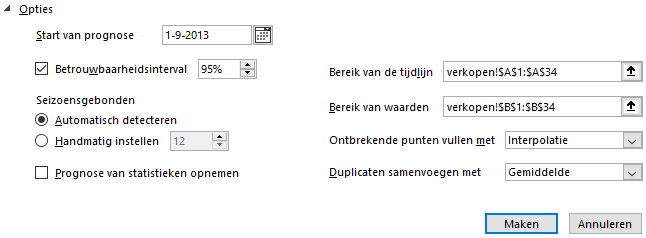
- Klik op Maken. Er wordt een nieuw werkblad gemaakt met daarin de historische gegevens, de voorspelde waarden, betrouwbaarheidsgrenzen (standaard 95%) en een grafiek.
De resultaten van de voorspellingen staan in Tabel 6.2 weergegeven.
| Datum | Voorspelling | Ondergrens | Bovengrens |
|---|---|---|---|
| 01-10-2013 | 4264177 | 3869915 | 4658439 |
| 01-11-2013 | 4033806 | 3639542 | 4428070 |
| 01-12-2013 | 4033625 | 3639358 | 4427892 |
6.6 Opgaven
Oefening 6.1 Autoverkopen
In het bestand autoverkoop.xlsx staan de de autoverkopen per kwartaal van 4 jaren. Maak met behulp van het Voorspellingenblad een prognose van de verkopen voor de vier kwartalen van jaar 5.
Oefening 6.2 Omzetvoorspelling
In het bestand bedrijfsomzet.xlsx staan de omzetten van een bedrijf over de jaren 2007-2015.
- Maak een spreidingsdiagram van de omzet tegen het jaar.
- Voeg achtereenvolgens de volgende trendlijnen toe; lineair, logaritmisch en exponentieel. Verzamel voor elk van deze trendlijnen de waarde van R-kwadraat. Maak op basis hiervan een keuze voor het meest geschikte model.
- Maak via de opties voor de trendlijn een voorspelling van de omzet voor 2016 en lees de waarde in de grafiek af.
- Experimenteer met de opties voor de trendlijn om uit te zoeken wanneer een omzet van €25.000.000 te verwachten is.
- Bereken een voorspelling van de omzet voor 2016 met een werkbladformule. Welke formule je hiervoor kunt gebruiken hangt af van het gekozen model.
- Maak m.b.v. het Voorspellingenblad een prognose voor de omzet van 2016, alsmede een 95% betrouwbaarheidsinterval hiervoor.
- Vergelijk de drie voorspelde waarden met elkaar.
Oefening 6.3 Televisieverkoop
In het bestand televisies.xlsx staan de verkochte aantallen televisies per kwartaal gedurende vier jaar.
- Maak een grafiek van de tijdreeks.
- Is er een trend of een seizoenspatroon in de tijdreeks te ontdekken.
- Maak een voorspelling van de verkoop voor de kwartalen van het volgende daar. Denk eerst na over welke prognosemethode je wilt gebruiken.